Часто наблюдаю, что ЛЭРС пытается считывать какие-то данные, начиная с даты постановки на автоопрос. Это происходит при каждом автоопросе, и приводит к длительному опросу, который отрубается только по таймеру “максимальная продолжительность опроса”. В “наличии данных” вижу, что данных за этот период в вычислителе нет. Странным мне кажется то, что опрос всегда начинается с даты постановки на автоопрос, и эта дата не сдвигается вперед, даже если вычислитель ответил, что в нём этих данных нет. Зачем постоянно пытаться считывать то, чего нет? На мой взгляд, в таком случае нужно автоматически сдвигать дату вперед, а не заставлять пользователей вручную снимать точки с автоопроса, а потом настраивать автоопрос заново. Прошу объяснить, для чего вообще ЛЭРС УЧЕТ хранит датупостановки на автоопрос? И почему она скрыта, её нельзя увидеть в настроенной точке учета?
Она нужна для формирования интервала автоопроса. Сервер анализирует интервал от даты постановки на автоопрос до сегодняшнего дня. Даты, за которые данные получены, или которые отсутствуют в приборе, исключаются. Опрашиваются только неопрошенные данные, которые в карте отмечены желтым или синим.
Система следит, чтобы дата начала автоопроса не уходила далеко в прошлое и корректирует ее если она старше чем 3 месяца. Это нужно для того, чтобы оптимизировать анализируемый интервал. Иначе из БД будет с каждым разом выбираться все больше данных.
Если система запрашивает данные, которые в карте отмечены красным или зеленым, приложите скрин карты и журналы опроса. С этим нужно разбираться предметно.
Проверил, на самом деле повторного считывания одних и тех же данных нет. Но теперь я заметил, что архивы считываются не в порядке возрастания или убывания дат, а каким-то странным образом. Вот, например, в приложенных журналах опроса видно, что при первом опросе (07.11.22 13-28) была попытка считывания часовых (их нет в вычислителе) за:
16.08.2022 8:00:00
16.08.2022 10:00:00
16.08.2022 12:00:00
16.08.2022 14:00:00 и так далее…
при втором опросе (07.11.22 21-59) была попытка считывания часовых за:
16.08.2022 7:00:00
16.08.2022 9:00:00
16.08.2022 11:00:00
16.08.2022 13:00:00 и так далее…
при третьем опросе (08.11.22 05-12) была попытка считывания часовых за:
16.08.2022 6:00:00
Поэтому, на первый взляд, мне показалось, что ЛЭРС УЧЕТ запрашивал одни и те же данные.
Спасибо за подробные разъяснения. Очень рад, что вы сделали автокоррекцию даты начала автоопроса, если она старше, чем 3 месяца. Я бы даже ограничил 2 месяцами.
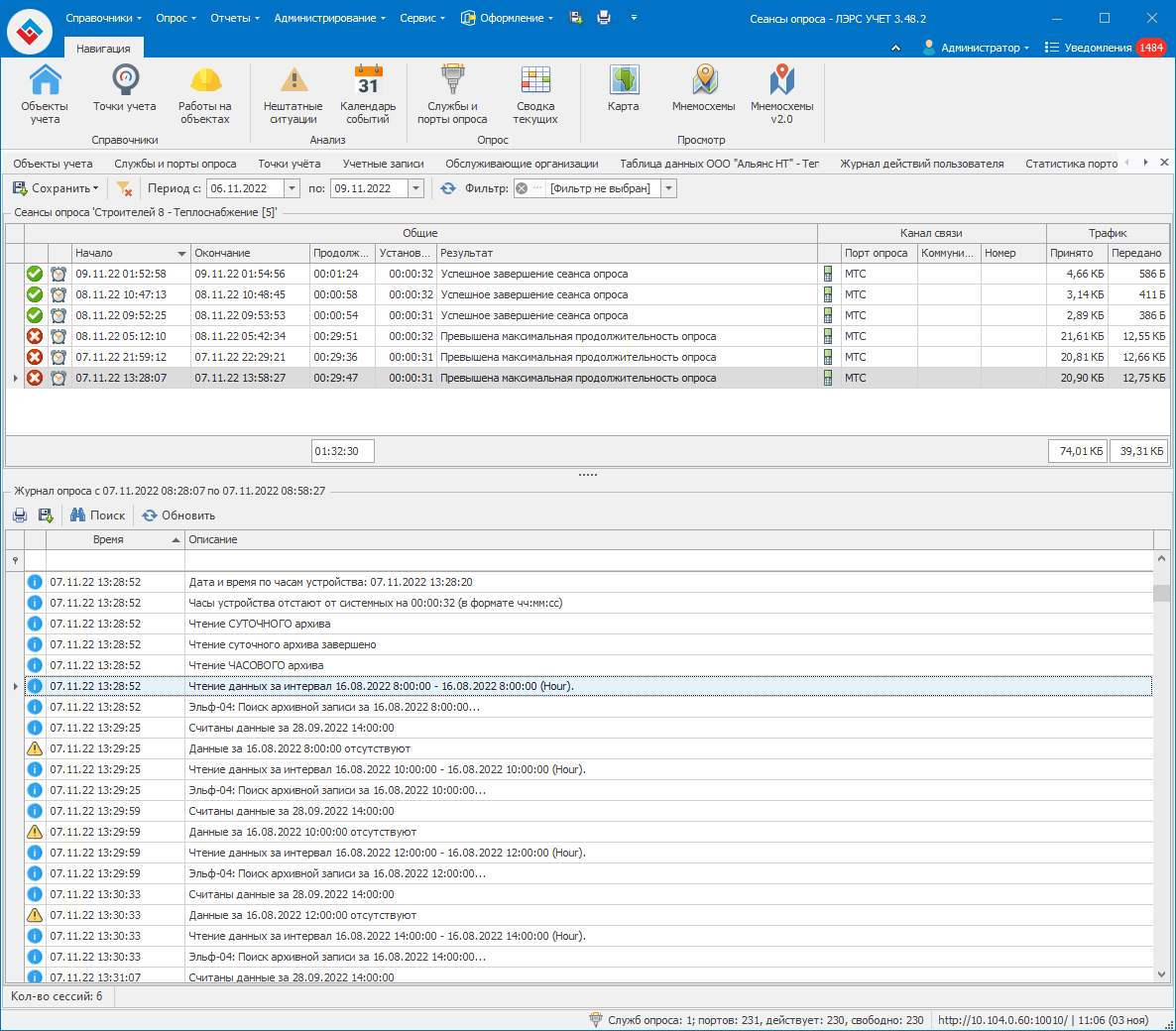
Журнал опроса 07.11.22 13-28.xlsx (18.4 КБ)
Журнал опроса 07.11.22 21-59.xlsx (22.0 КБ)
Журнал опроса 08.11.22 05-12.xlsx (17.8 КБ)
Приложите пожалуйста дампы обмена для этих журналов опроса.
Дампы обмена:
dump.МТС.2022-11-07.log (348.6 КБ)
dump.МТС.2022-11-08.log (175.4 КБ)
Скиньте пожалуйста скриншот таблицы наличие данных для этой точки учёта за период с 1 июня по текущий месяц.
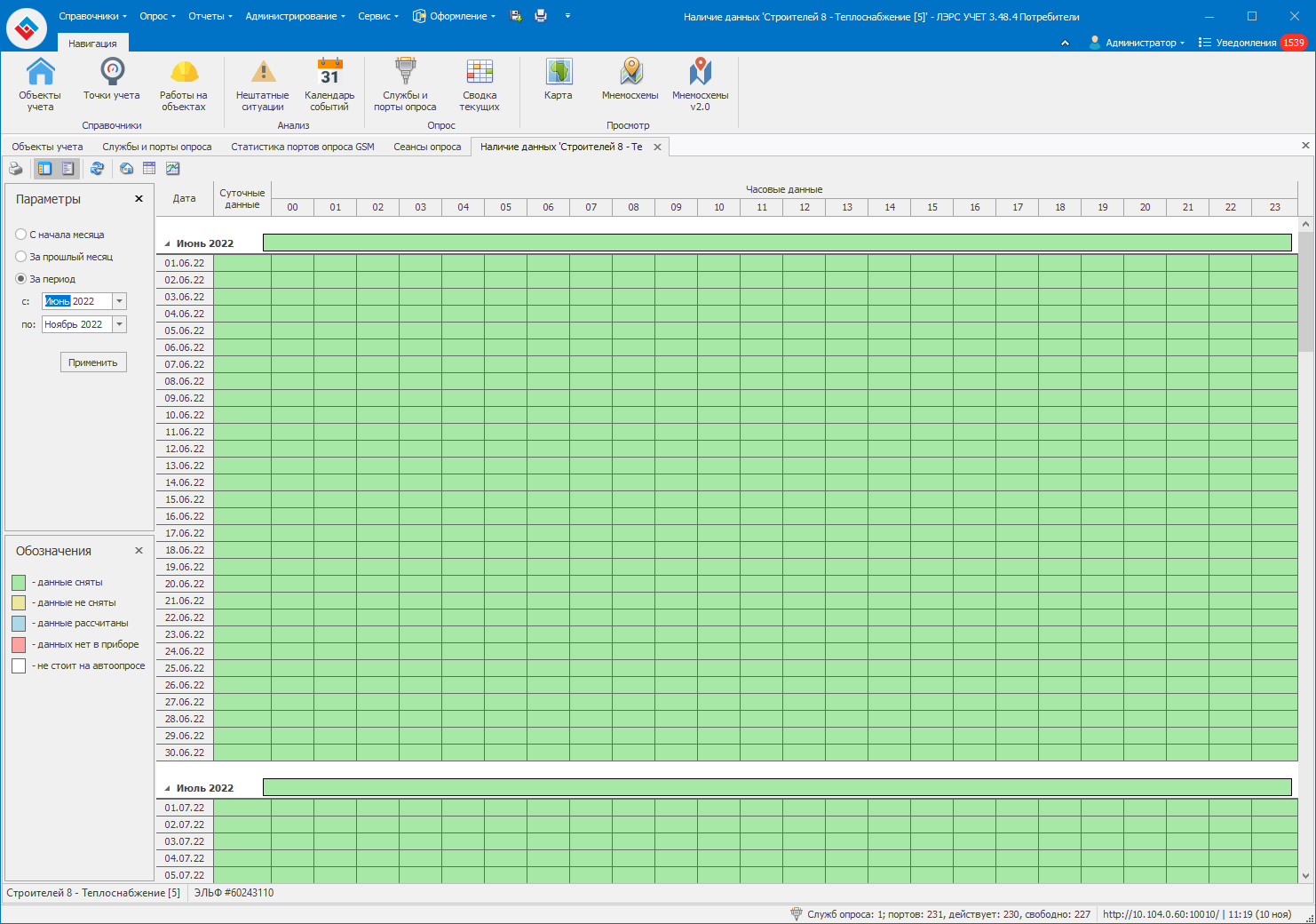
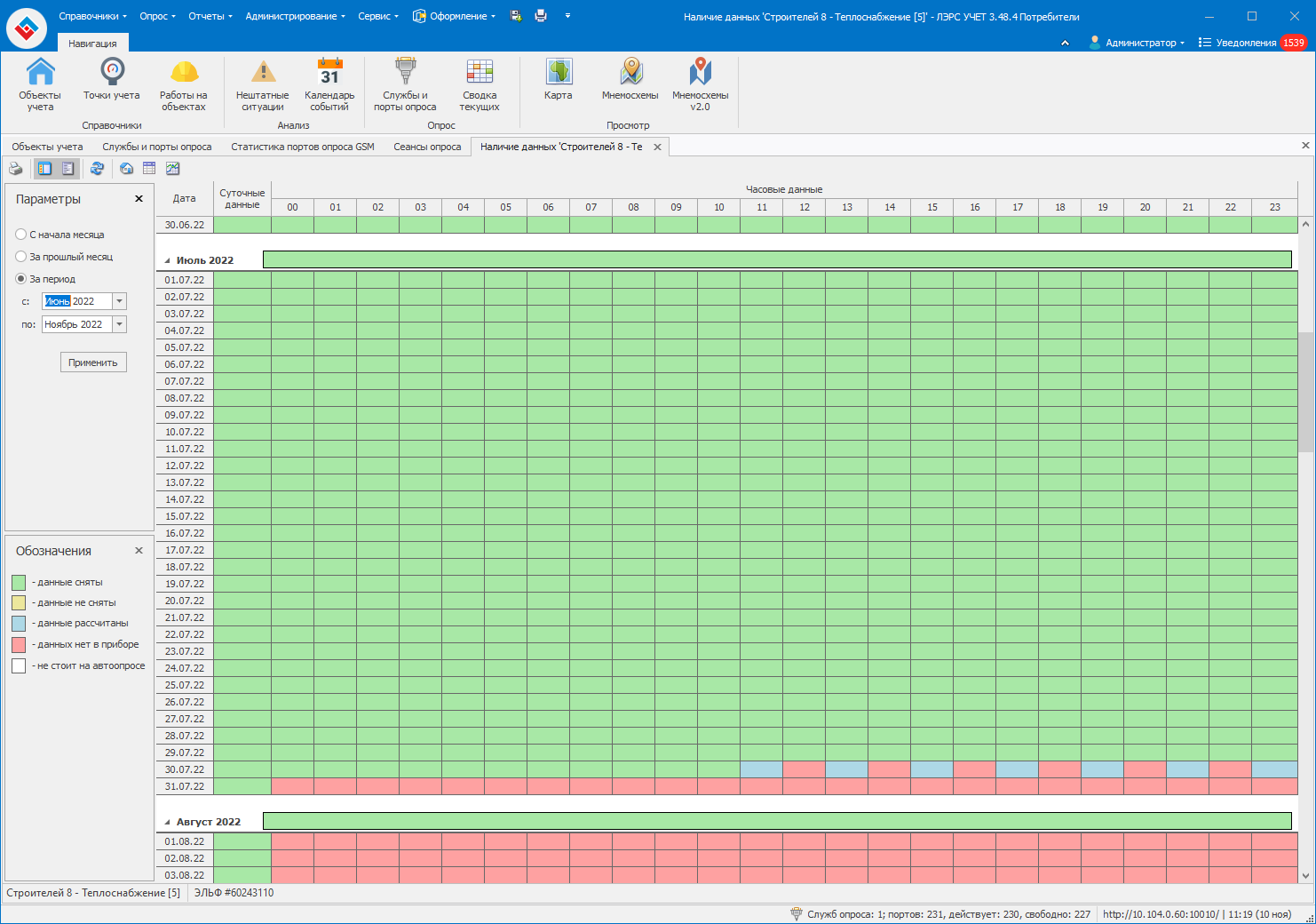
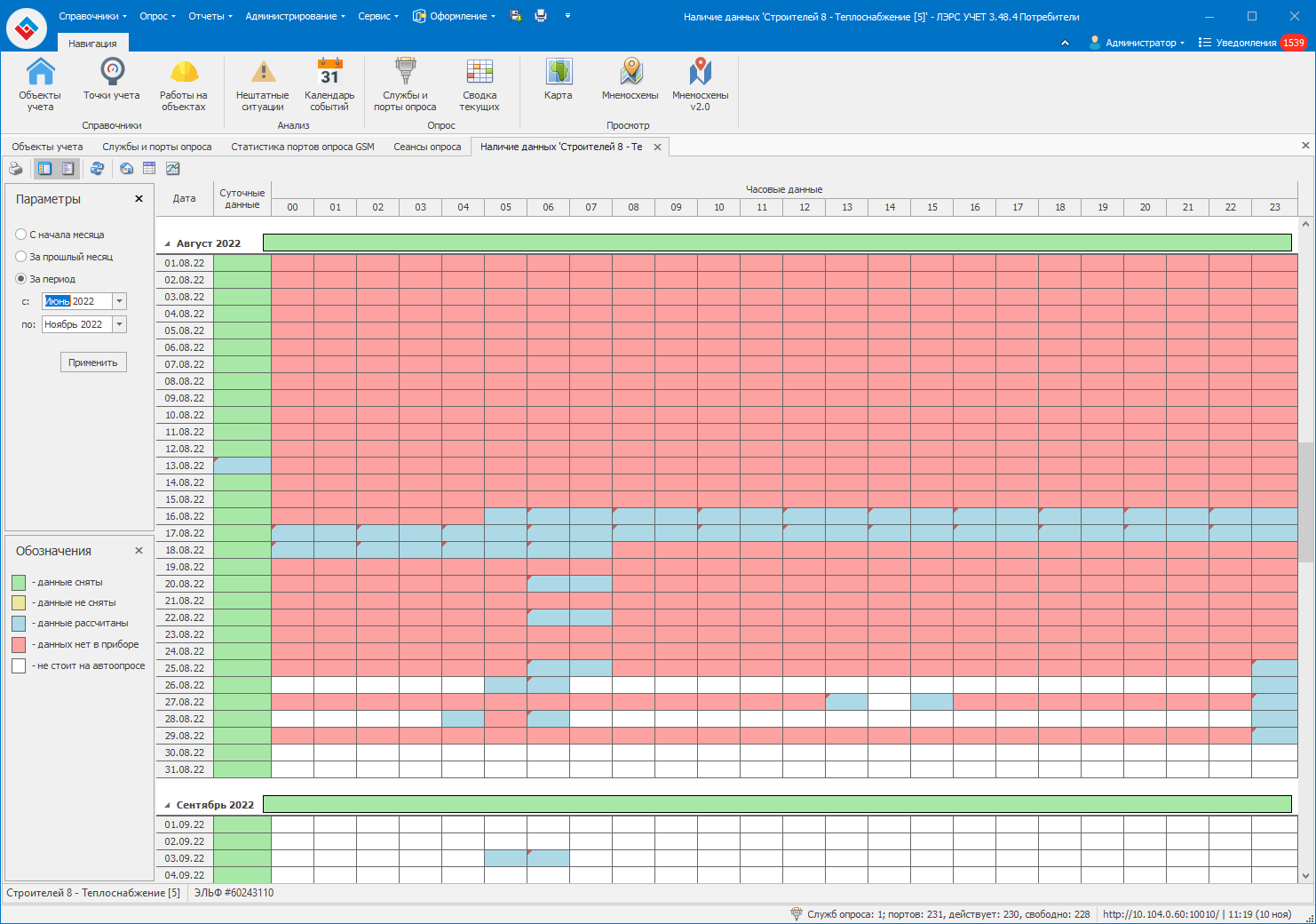
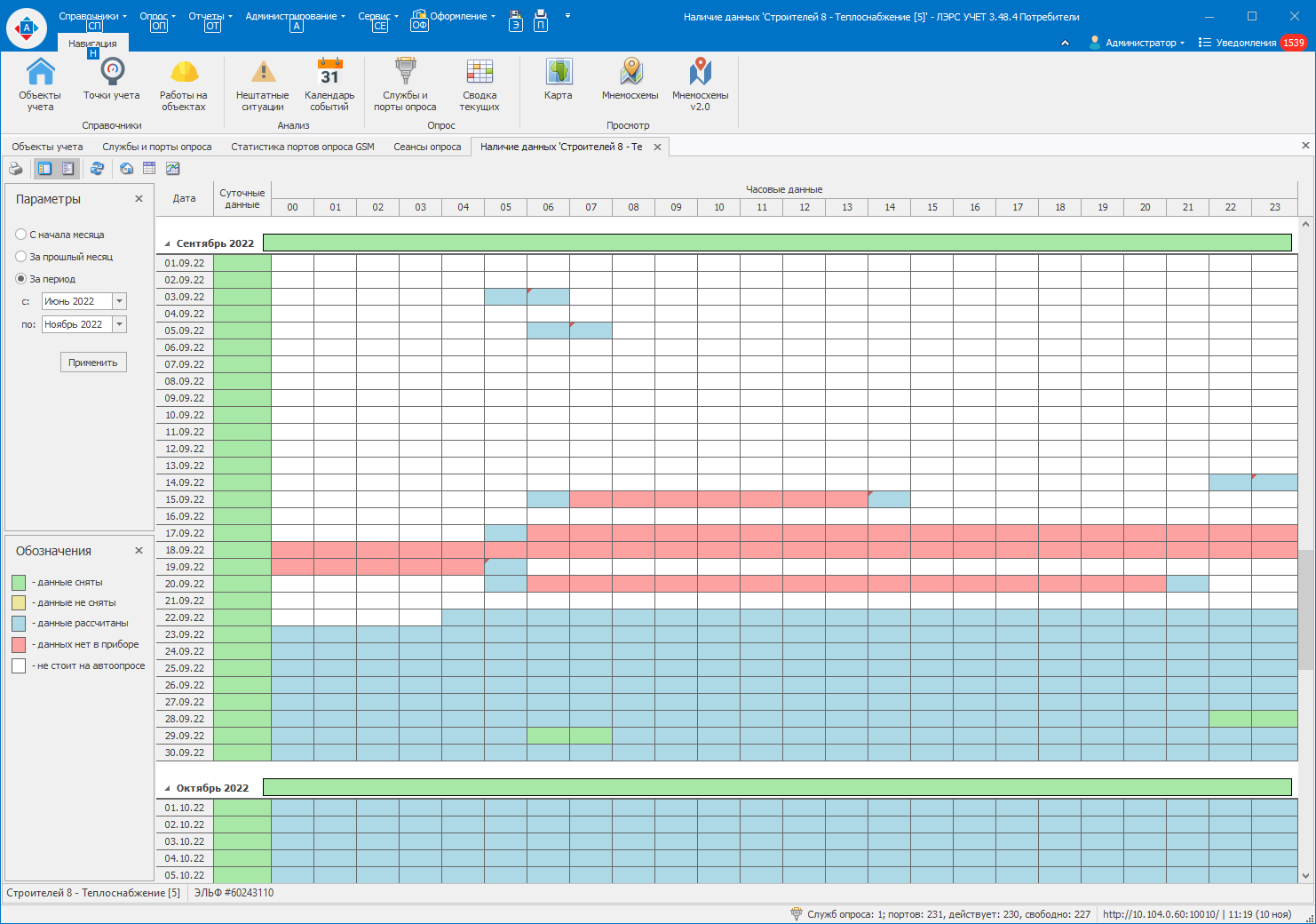
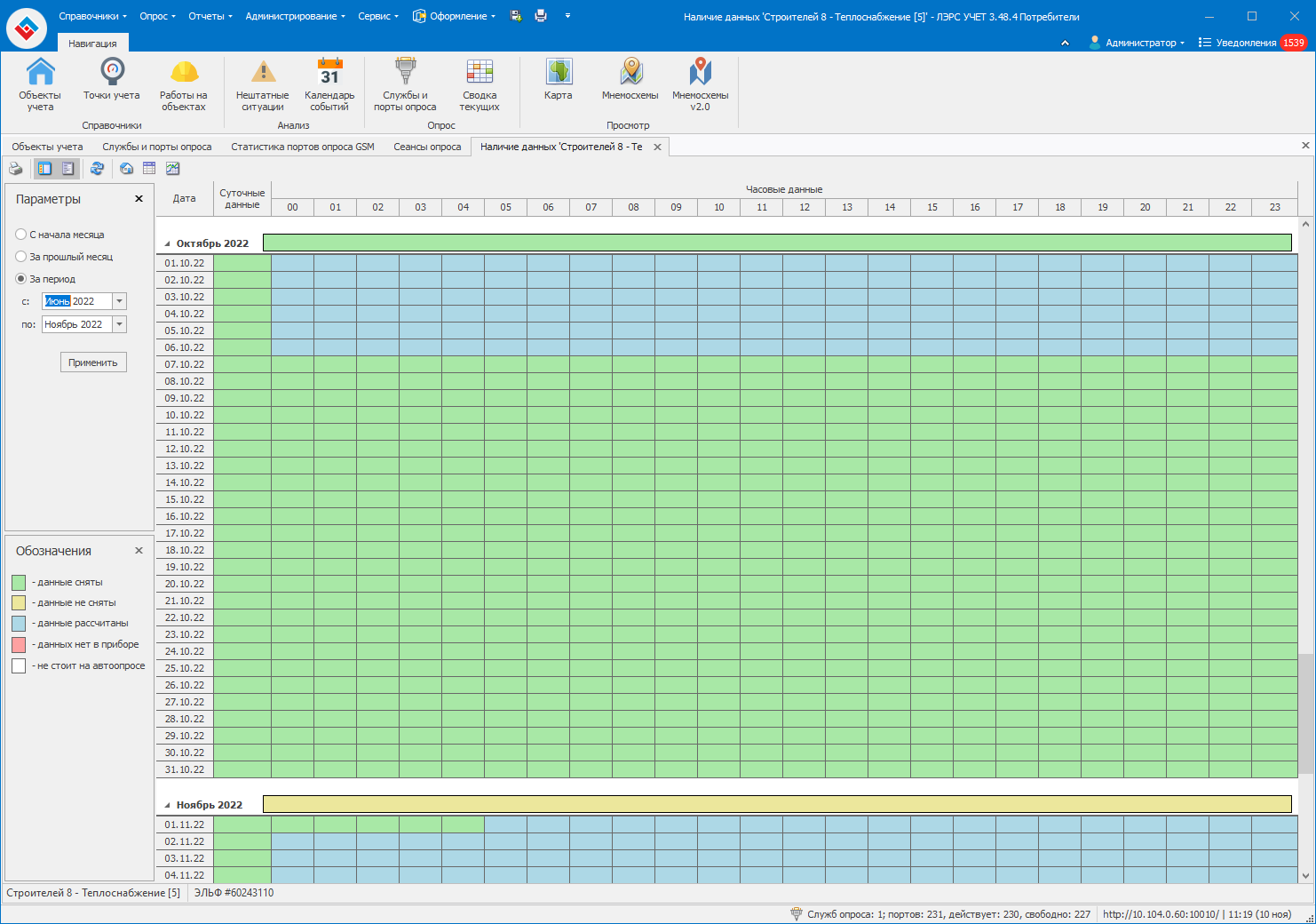
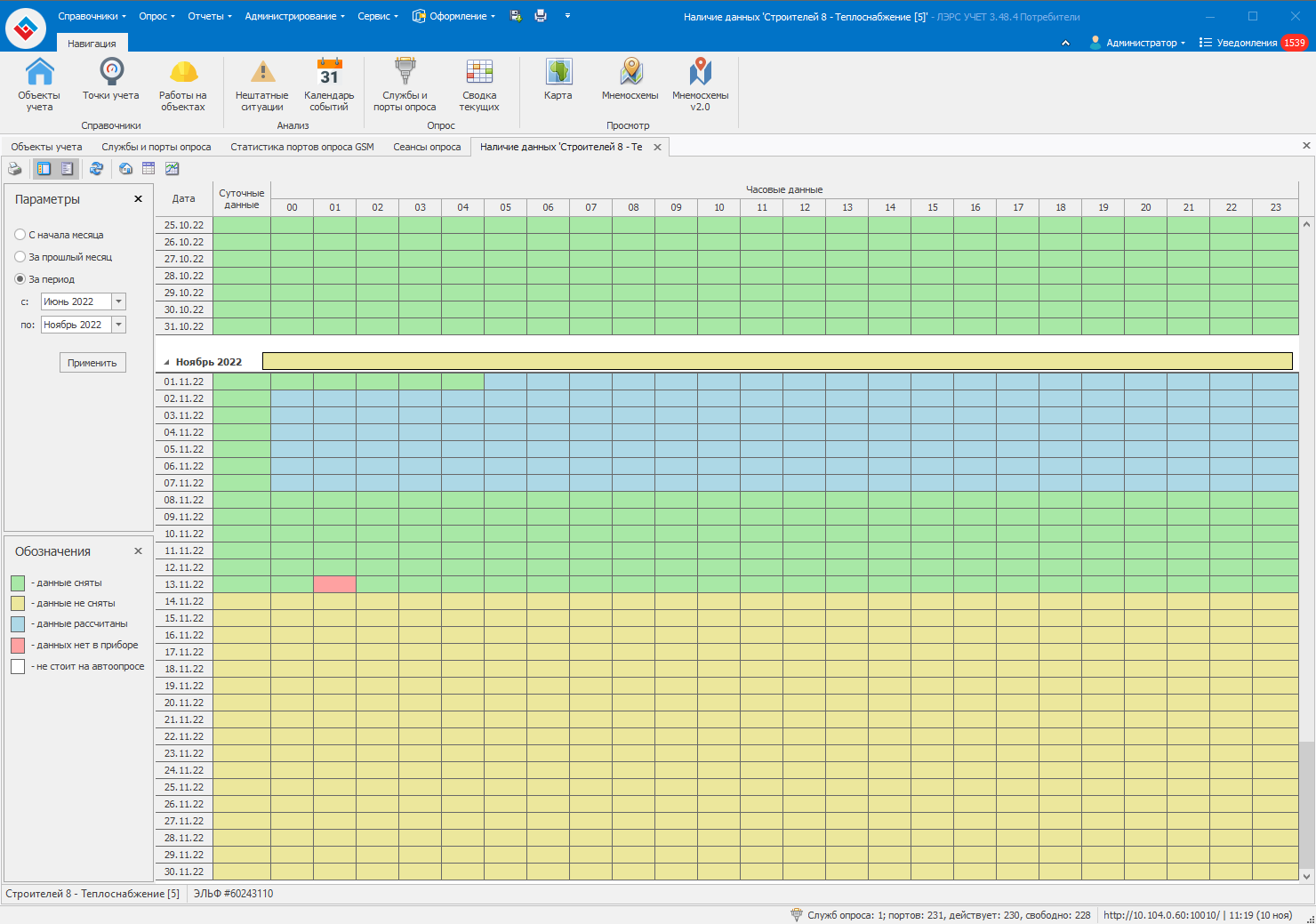
Нам необходима резервная копия вашей БД для воспроизведения ситуации.
А в чём хоть проблема? Я извиняюсь, ошибся, повторного считывания одних и тех же данных не обнаружено.
Мы хотим выяснить по какой причине происходит попытка считать часовые данные за довольно странные периоды, о которых вы писали ранее:
Мы восстановили вашу БД. Судя по всему такое дробление происходит из-за того, что некоторые часовые записи помечены как “данные рассчитаны и отсутствуют в приборе”. Получается при первом опросе рассматриваемой точки запрашиваются только данные с пометкой “данные рассчитаны” и по его выполнении они помечаются как “данные отсутствуют в приборе”. При этом данные с пометкой “данные рассчитаны и отсутствуют в приборе” после этого опроса становятся просто “данные рассчитаны” и при повторном опросе запрашиваются они. Собственно поэтому у вас и происходит ситуация, которую я цитировал выше. Все проверки проводились в текущей версии 3.48.4.
Для обхода такой ситуации вы можете запустить ручной опрос часовых данных начиная с даты, за которую наблюдается такая ситуация, дождаться возвращения результата по нескольким таким часовым периодам, после чего остановить опрос. В карте наличия данных после него часовые метки, участвовавшие в опросе, будут помечены как “данные отсутствуют в приборе”, а все метки “данные рассчитаны и отсутствуют в приборе” станут просто “данные рассчитаны”. Повторный ручной опрос должен пометить все отсутствующие данные и начать опрос имеющихся в приборе.
Теперь мне всё понятно.